When developing an application using JPA, there is always a question: what should we create first? Should it be a proper object-oriented JPA entities set describing the business domain or a highly optimized and normalized database schema?
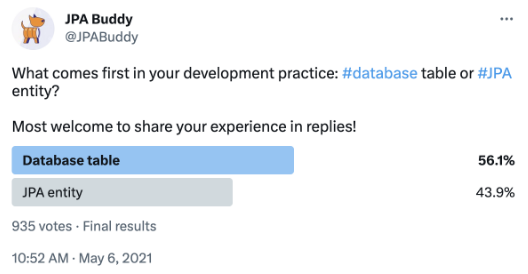
In the JPA Buddy team, we conducted a survey, and the DB-first approach won by a small margin. It means that it is worth digging a bit deeper into this question.
In this article, we’ll review both approaches and give some recommendations regarding this “egg-and-chicken” question.
JPA-first approach
Adherents of this approach claim that creating JPA entities first leads to a more intuitive and clean application design. The application interacts with domain objects rather than database records, and the database is only one of many data sources (e.g., message queue, external REST service, or any other source). Developers just need to create classes based on the business domain specification and annotate them properly to start working with the database. In the ideal case, they shouldn’t even consider how objects are persisted and fetched from the storage. It is JPA’s job to save and load data somehow.
This approach facilitates faster development since the database schema is created and updated simultaneously with the rest of the application. JPA can generate DDL to reflect object model changes. For example, in the case of Hibernate, we can use the hibernate.ddl-auto (a.k.a., hbm2ddl) feature to generate and execute scripts for creating or updating a database schema according to the JPA entities structure.
During the initial stages of the application development, the JPA-first approach in conjunction with automatic schema recreation can save a lot of time. While we discover and implement business requirements, the object model changes a lot. With the automatic DB creation feature, we do not need to carefully plan the database schema updates to run and test the application during development.
However, when using the JPA-first approach, we need to consider some things.
First, the hbm2ddl feature is not recommended for production use. There are some issues with using it:
- Lack of control. There is no way to set up proper Java type to database type mapping. Additionally, Java type converters are not supported.
- No rollback support. Hibernate does not offer a way to undo schema changes if something goes wrong.
- No DB version control. It is difficult to track changes to the schema over time and revert to previous schema versions if necessary.
- Data loss. Any changes to the JPA entities result in Hibernate automatically updating the schema, potentially causing data loss.
A proper alternative is using DB versioning tools such as Liquibase or Flyway.
Second, Hibernate does not create a highly optimized DB schema. It creates a generic schema that will work with the current JPA object model. Scripts generated by Hibernate can serve as the initial version of the migration script for these tools. If we want to utilize all database-specific features, we need to carefully tune this DDL, and use it in the DB versioning tools scripts. After switching to DB versioning tools, we need to set hibernate.ddl-auto property to validate to ensure that the database and JPA model are always in sync.
Third, as soon as we introduce DB versioning tools to the project, we’ll need to implement DB schema migrations manually based on the JPA model changes. Fortunately, we can use some tools to simplify our job:
- Liquibase-hibernate plugin. It is a command-line-based tool used solely for Hibernate. It does its job but lacks IDE integration, so we’ll need to pull generated scripts into the codebase and review them separately.
- JPA Buddy – plugin for IntelliJ IDEA Ultimate and Community. Provides extended functionality for DB script generation for Flyway and Liquibase. The plugin supports script preview, Java type converters, etc.
- Dali JPA Tools is the only option for eclipse IDE users. It does not integrate with DB migration tools, so we need to add generated SQL to DB migration scripts manually.
Conclusion on the JPA-first approach
The JPA-first approach is preferable when our application is the only place where the data model (DB schema) can change over time. This approach allows us to implement DB schema quickly in the early stages of the application lifecycle thanks to the automatic schema recreation feature. For production use, we need to introduce DB version tools to avoid problems with schema updates, such as data loss.
DB-first approach
Creating a database first allows designing and testing the database schema before the application is built, leading to better performance and a clearer understanding of the data requirements. We can utilize all DB-specific features and create a highly optimized database schema. This also leads to easier collaboration with other application development teams, as well as database administrators or business analysts. In addition to that, it lets us share the DB between applications while each application can (potentially) use its own JPA model. When we follow the DB-first way, all business requirement changes should be applied to the DB first and then reflected in the JPA model(s).
Some developers prefer this approach to JPA-first because “the database always outlives the application”, but this is not entirely accurate. The data, not the database schema, outlives the application. Schema changes are inevitable because business requirements constantly evolve. We’ll need to update our database schema anyway.
When we use the DB-first approach and JPA as the data access framework, we should always consider this. JPA needs a specific approach when implementing a DB schema to work most efficiently.
As an example: Hibernate (the most popular JPA implementation) uses sequence number caching for DB-generated IDs. By default, Hibernate assumes, that a sequence increment equals 50. So, it is important to create a sequence with a proper increment parameter. Otherwise, our application either just won’t start or will generate non-unique IDs or execute too many queries for ID generation.
Another prominent example is the One-to-One relation. From the relational DB view, such a relation does not make sense in most cases, but its existence can be explained by the object domain model. For example, a user profile and credentials can be stored in a single table in a database. Still, for the application, it would be better to fetch this data separately for performance and security. Hence, our database should reflect it in the schema design.
So, creating a JPA model over any arbitrary database is not a simple task. Not all schema design decisions can be mapped directly to JPA entities. If you have ever tried to create a JPA data model for an existing (legacy) database created without JPA-specific conventions, you know it’s pretty painful.
For the DB-first approach, it is natural to use DB versioning tools from the beginning of the development. As the initial version for the database schema DDL script, we can use the SQL generated by JPA but tuned according to the particular DB version. While development continues, after updating the database schema, we need to update JPA entities based on these changes. As with the previous approach, we can change the Java code manually, but special tools are preferable. These tools will help you to migrate your database changes to JPA entities effortlessly and with minimum problems:
- Dali JPA Tools
- JPA Buddy
- JPA Support for IntelliJ IDEA Ultimate. Similar to previous tools, it also can generate managed entity classes and object-relational mappings for them by importing a database schema. It cannot generate diff SQL for the JPA-first approach though.
Conclusion on the DB-first approach
The DB-first allows us to use DB-specific features and create a highly optimized schema for the application. However, we should remember that it does not isolate us from JPA completely. To achieve a proper performance level, we need to consider that JPA frameworks rely on some conventions, and we need to apply these while designing the schema. The DB-first approach works best when we have a database shared between different applications, so it is feasible to start changes from the common area and then propagate them to the JPA models in applications.
JPA-first vs DB-first
As they say: “All theory, dear friend, is grey, but the golden tree of actual life springs ever green.” Let’s look at an example to understand better how both approaches work.
When a new business requirement arrives, we, as developers, usually create a code branch to implement this requirement. In the case of DB-related code, we also need to get a proper DB version. If we use DB-versioning tools, it should not be a problem, since we have all update scripts in the codebase.
As soon as the branch is created, we start development. We should note that business requirements are usually implemented in the application code. We typically need to implement some business logic that requires application model changes. And those changes may impact data storage hence DB schema. So, what are the steps in the feature implementation?
JPA-first approach
- Update JPA entity according to new requirements.
- Generate update DDL and apply it to DB. We can even use
hbm2ddfor generation, but modern tools like JPA Buddy allow us to generate update scripts by comparing the JPA model and database. - Implement and test business logic.
- Merge code into the main branch. While merging, we need to remember that the “main” database version could change. So, we need to compare our JPA model with this database and create a diff script for a DB versioning tool. Again, it is easy to use with proper tooling. It can be done using Liquibase (though we need to use CLI), Intellij IDEA JPA support, as well as JPA Buddy.
- After that, we can commit our changes. Please note that the JPA model is the source of truth for the DB schema. We always update the database according to JPA changes and validate schema against the JPA model.
DB-first approach
- Analyze requirements and update the DB. For this case, we usually use GUI tools to update the DB, because it’s just faster. In most cases, we need to update the DB more than once to get the schema right. Final DDL can be generated before the merge.
- Update the JPA model according to DB changes. This is the trickiest part of the process. Most tools like Dali JPA or JPA Support can generate entities based on the DB tables but do it for the whole entity. So, we need to cherry-pick new changes and incorporate them into our codebase to avoid overriding existing entities' code. It is important because generators do not create lifecycle callbacks, validation rules, type conversions, etc. The only tool that can generate incremental JPA entity updates based on DB is JPA Buddy as we discussed earlier.
- Implement and test business logic.
- Merge code into the main branch. While merging, we need to remember that the “main” database version could change. So, we need to compare our development database with the “main” database and create a diff script for a DB versioning tool. Again, it is easy to use with proper tooling. Liquibase can do it for us as well as JPA Buddy.
- A side note: despite the fact that we use the DB-first approach, we should validate the schema against the JPA model anyway.
Tools matter
As we can see, both approaches work fine. There is not much sense to talk about a “pure” approach that “must” be used during the whole application development cycle. If we use JPA in our application as a data access layer, the JPA-first approach may look slightly better for two reasons:
- Business requirements are usually implemented in the code first
- We have a single DB schema description – the JPA model, anyway. So, our database will always be validated against this model.
The only challenging task for both approaches is generating updates for DB or for Java code. Proper tooling is key to efficient and error-free updates. Comparing a JPA model with DB or DB with another DB, cherry-picking differences, and creating Java or SQL require some effort.
If you use Liquibase and are not afraid of the CLI and writing config files, then you can use it for diff generation for the JPA-first approach and to compare two databases. Liquibase won’t update the JPA model for you. Though JPA Buddy does it and it supports Liquibase too.
If you use Flyway or do not want to update JPA entities manually after the DB update, JPA Buddy looks like the only choice. It will help you with diff script generation for Flyway as well as able to update JPA entities based on DB tables. JPA Buddy can merge DB changes into the existing code, instead of regenerating the whole entity like others by cherry-picking changes. It also supports association detection, even many-to-many ones. Thanks to IntelliJ IDEA API, the plugin “understands” code and project structure, so it updates entities annotated with Lombok, moreover update is applied not just to entities but also to corresponding DTOs.
Using Spring Data JPA, Hibernate or EclipseLink and code in IntelliJ IDEA? Make sure you are ultimately productive with the JPA Buddy plugin!
It will always give you a valuable hint and even generate the desired piece of code for you: JPA entities and Spring Data repositories, Liquibase changelogs and Flyway migrations, DTOs and MapStruct mappers and even more!
Conclusion
Each approach has its benefits, but we usually use the “hybrid” approach. We start with JPA entities, generate the first version of the database and then tune it based on our needs. Sometimes, we may need to update the DB first and then move changes to JPA. Usually, it’s about performance (indexes, denormalization, etc.) or data types mapping. When business requirements change, updating the JPA model first is preferable because we deal with domain objects in the application, so the model is the source of truth.
If a database is shared between different applications, using the database-first approach is generally recommended. In this approach, the database schema is the source of truth, and each application that accesses the database generates its own JPA (or non-JPA) entities based on the schema.
It's essential to have a well-defined process for managing changes to the database schema and to ensure that all applications are updated appropriately when changes are made. Generally, it's best to use a database migration tool to manage schema changes in a versioned and repeatable way. Also, IDE tools are important. Such tools can significantly simplify change management. For example, JPA Buddy can generate DDL for schema changes and also update your Java code based on DB objects, combining techniques used for both JPA-first and DB-first approaches.