DTO is probably the most straightforward pattern in object-oriented programming. What could be the motives for using DTOs in our applications? How to create them properly? Is Spring Data JPA projection a proper DTO? In this article, we’ll try to answer all these questions.
Introduction: what is DTO?
Let’s start with the definition of DTO. According to Martin Fowler , DTO is: “An object that carries data between processes in order to reduce the number of method calls. When you're working with a remote interface, such as Remote Facade, each call to it is expensive. As a result, you need to reduce the number of calls... The solution is to create a Data Transfer Object that can hold all the data for the call.”
So, initially, DTOs were intended to be used as a container for remote calls. In a perfect world, DTOs should not have any logic inside and be immutable. We use them only as state holders. Nowadays, many developers create DTOs to transfer data between application layers, even for in-app method calls. If we use JPA as a persistence layer, we can read an opinion that it is a bad practice to use entities in the business logic, and all entities should be immediately replaced by DTOs.
We recently introduced DTO support in JPA Buddy plugin. The plugin can create DTOs based on JPA entities produced by data access layer classes and vice versa – create entities based on POJOs. This allowed us to look at DTOs closer and see how we can use them on different occasions. For the sake of simplicity, we assume that we use Spring Data JPA to persist data and Spring Framework as the main framework in all our examples.
Where do we need DTOs?
Most applications use “layered” architecture now. There are usually three layers: data access, business logic, and external API layer.
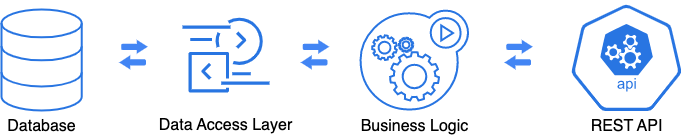
We use data model classes in the data access layer: JPA Entities or POJOs, depending on the data access framework. The question is: where we may need DTOs?
DTOs for API layer
The data model evolves; it is a well-known fact. It means we need to change data model classes (entities). If we use data model classes directly in the API, it means API changes. Therefore, we need to change all API consumers accordingly. This is not always possible for external clients that may be developed outside our company. Therefore, we need to use separate classes for data transfer. Sounds familiar? That’s precisely what Fowler describes as the DTO pattern! So, we can introduce DTOs in the API layer and convert entities to DTOs right before sending data. After receiving data from API clients, we also need to convert DTOs to entities. So, one reason to introduce DTOs is to set up a stable API model.

Another reason – hide some data in the application API. For example, it will not be wise to send the whole UserProfile entity with its password hash via the network to an unknown client. One more example is role access. API consumers may need different data depending on their access level. Talking about the same UserProfile entity: the role ADMIN may need full info about a user. From the other side, when the same API endpoint is called with the ANONYMOUS role, we should return only the profile name, and that’s all. In this case, DTOs are very useful. We need to create two DTOs: FullUserProfileResponse and BasicUserProfileResponce, and convert data into one of these classes before sending. With this approach, we don’t expose “secret” data.
Entities vs. DTOs on the business layer
As was told earlier, the domain object model is usually the same as data storage objects. If we use JPA, we can even generate a database schema based on our object model. When domain objects evolve, we can update data storage using such tools as Liquibase or Flyway or something built on top of them like JPA Buddy. So, in this case, creating a separate “domain model” is not a hard requirement. We always need to change business logic according to new changes in the data model. There is no sense in converting the “data store model” into the “domain model” – it will be just additional work on supporting two models and conversion code.
It looks like there are three main reasons to return DTOs from the data access layer and map them to a domain model. The first reason is to represent the data view. For example, we can select a purchase order and add a number of order lines as an additional field. Or a total order sum. Or both. So, when we select additional calculated information from a database, DTOs are necessary. The second reason is reusing old data storage and building a brand-new domain model over it. We should use it when migration from the old data store is impossible. The third reason – we use a “flexible” data store schema. The latter can be implemented to support dynamic fields or even use the entity-attribute-value (EAV) approach. Also, some NoSQL storage drivers can return simple maps, so we can treat them as DTOs and map them to proper Java objects. To map the data store model to the business model, we can use custom repositories described in the Repository design pattern and build our business logic over them.
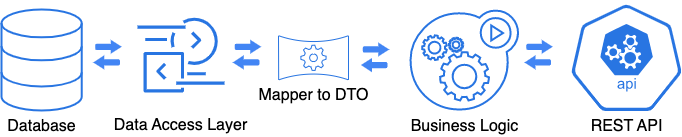
“No-DTO” approach
Developers usually build a data model based on the business domain requirements. API represents data relevant to the application domain.
In some cases, we don’t need DTOs at all. Entities can transfer data in the same way as DTOs. Of course, we need to consider potential problems like serialization and transaction management to avoid LazyInitException with JPA entities. If we take into account all these corner cases, this approach is perfectly viable.
For example, we can look at applications that use server-side rendering for their UI. If we don’t have an API for external clients, we should not send data to them. Hence, we can use entities directly in the UI. For example, Jmix framework uses this approach. It uses Vaadin as the UI framework, which uses small JSON chunks of data to send UI updates to the client browser, not the data itself. Jmix uses entities in its UI directly, so no DTOs are required. If an application requires an external API to exchange data with an external consumer, we should consider using DTOs.
Another example – is the Blaze Persistence framework. Apart from rich Criteria API for JPA(including CTE, UNION, etc), it introduces the concept of EntityViews. Those are java interfaces that not just limit access to entity attributes but also can do some calculations similar to Spring Projections:
@EntityView(UserProfile.class)
public interface UserProfileView {
@IdMapping
Integer getId();
@Mapping("CONCAT(firstName, ' ', lastName)")
String getFullName();
}
This is how we can use it in the code:
CriteriaBuilder<UserProfileView> cb = criteriaBuilderFactory.create(entityManager, UserProfileView.class);
cb.where("username").like().value(name+"%").noEscape();
CriteriaBuilder<UserProfileView> catViewBuilder = evm.applySetting(EntityViewSetting.create(UserProfileView.class), cb);
List<UserProfileView> catViews = catViewBuilder.getResultList();
So, in the case of Blaze Persistence, we don’t need DTOs. We can use entity views instead and fetch them directly from the database. No mappers are required.
OK. We have figured out “where” we need DTOs (when we need them at all). Now it is time to answer the question “how to work with them”.
How to map an entity to DTO?
Assume that we have an entity “UserProfile” (its code below), and we need to map it to a DTO (or DTOs) after fetching from a database. Which options do we have?
@Entity
@Table(name = "user_profile")
public class UserProfile {
@Id
private Integer id;
@Column(name = "first_name")
private String firstName;
@Column(name = "last_name")
private String lastName;
@Column(name = "username")
private String username;
@Column(name = "password")
private String password;
}
The first option is using POJOs. POJOs are just regular java classes that contain only properties and getters. They are dead simple, not bound to any framework, and usually, there is no problem with their serialization.
It is a good practice to make DTOs immutable. Their purpose is to transfer data from one endpoint to another, so we should be sure that this data is not changed accidentally in between. Therefore, it is recommended to make all properties in our POJOs final and implement getters only.
To convert entities to POJO DTOs, we can implement a custom code. This is a simple task, but it brings a lot of boilerplate code to the codebase, and we need to support it. It’s a better idea to use libraries and framework features for such conversion.
POJOs and Hibernate
Hibernate contains a built-in feature for creating any class right in the HQL query. Let’s look at the following example:
Query<UserDto> query = session.createQuery("select " +
"new com.example.UserDto(u.id, u.username) " +
"from UserProfile u", UserDto.class);
It is the simplest way to create DTOs without mappers and additional libraries, but it has some limitations. For a starter, such queries contain a mix of data selection and mapping logic, which is hard to support. Second, there is no type validation; the query is just a string. The next point – we’ll need to implement DTO-to-entity conversion manually anyway. And finally, it is not reusable. If we want to map various DTOs for the same query result, we should either copy and paste the query code or build it from separate strings, which is hard to support also. As a result, this way is good for fast prototyping. For production use, we’d recommend other options like separate mappers.
POJOs and mappers
As it was told earlier, when introducing POJO-based DTOs, we should implement mapper classes to convert entities to POJOs (and back). Libraries like MapStruct or ModelMapper simplify this task. They can generate mappers automatically, but still, we need to write conversion code like this (example for MapStruct):
userProfileRepository.findAll()
.stream()
.map(userMapper::toDto)
.collect(Collectors.toList());
We also need to remember that all libraries rely on some conventions and cannot map any entity to any DTO. For example, this kind of DTO:
public class UserDto implements Serializable {
private final Integer id;
private final String username;
}
can be mapped to the UserProfile without any problems. If we need to add something extra, like the fullName property and a getter for it, we need to add some code to our mapper:
@AfterMapping
default void calculateFullName(UserProfile profile, @MappingTarget UserFullNameDto dto) {
dto.setFullName("%s %s".formatted(profile.getFirstName(), profile.getLastName()));
}
As you can see, implementing DTOs as POJOs has pros and cons. They are simple to implement, but we need to remember to keep them immutable and implement mappers or use 3rd-party conversion libraries.
Records
Starting from Java 14, we have another option for DTO implementation – records. As the documentation says: “Like an enum, a record is a restricted form of a class. It’s ideal for "plain data carriers," classes that contain data not meant to be altered and only the most fundamental methods such as constructors and accessors.”
Records are an excellent replacement for POJOs as DTOs. They are immutable by default and contain accessors only. For our UserProfile, a corresponding DTO will look like this:
public record UserDto(Integer id, String username) implements Serializable {}
It is great that mapping libraries support records, though not all of them. The most popular one – MapStruct, does it, in contrast to ModelMapper, which is still struggling. The mapper code will not be different from the one we used for POJOs (for MapSruct).
So, with records, DTO declaration is much simpler, but we still need to implement (or generate) mappers.
We recommend using records over POJOs if you use modern JDK. Just remember one thing: records do not support inheritance. If you prefer creating class hierarchies like BaseDto(DTO that contain only ID), BaseNamedDto (DTO that contains ID and name), etc., records might not work for you.
Spring Data JPA Projections
When talking about mapping entities to DTOs, we should mention Spring Data projections. This feature works in conjunction with Spring Data repositories and allows us to avoid mappers. Let’s look at the same example as before: we need only some fields from the UserProfile entity. With projections, we can filter unnecessary fields during data fetch. We need to implement either an interface or a class-based projection to do this. Class-based projections are just POJOs that we described earlier, so in the following examples, we will focus on interface-based projections:
public interface UserInfo {
Integer getId();
String getUsername();
}
Interface-based projection DTOs are immutable, can be serialized automatically, and we don’t need to write mappers for them. In addition, Spring Data optimizes queries according to a projection field set. Spring Data will only generate a query for our projection listed above to select the id and username fields. This significantly reduces network traffic to the DB. The other beauty of projections is the possibility of using Spring Expression Language. Let’s add the fullName property to the projection:
public interface UserInfo {
Integer getId();
String getUsername();
@Value("#{target.firstName + ' ' + target.lastName}")
String getFullName();
}
As you can see, the code is simple and straightforward. Also, we can reuse parts of a projection in another projection, which adds even more flexibility to our DTOs.
If we need to return different DTOs from the same request, we can use dynamic projections. This will work perfectly when we need to return a different set of fields for the same request depending on the invoker’s access rights. All we need to do is to create UserDto and UserFullNameDto projections and specify them in the Spring Data repository.
<T> List<T> findByUsernameLikeIgnoreCase(String username, Class<T> type)
List<UserDto> users = userProfileRepository.findByUsernameLikeIgnoreCase("john", UserDto.class);
List<UserFullNameDto> usersFullName = userProfileRepository.findByUsernameLikeIgnoreCase("john", UserFullNameDto.class);
As we can see, the Spring Data projections feature provides an efficient and flexible approach for creating DTOs when we need to fetch only selected properties. Projections can be applied to the data access layer and passed to the business logic layer or the API. The downside of using projections in the business layer – we cannot lazily fetch additional properties in contrast to regular entities if needed.
Conclusion
It is hard to avoid DTOs in modern business applications. The most common reason to use them – stabilize the application's external API and hide some information from the data transferred via this API.
In some cases, we may need to use DTOs to transfer data from the data layer to a business layer of an application, but this is more an exception than a rule. The data storage model is usually the same as the business model. If it is not the case, use custom repository classes to hide data access and model mapping code behind them.
Using Spring Data JPA, Hibernate or EclipseLink and code in IntelliJ IDEA? Make sure you are ultimately productive with the JPA Buddy plugin!
It will always give you a valuable hint and even generate the desired piece of code for you: JPA entities and Spring Data repositories, Liquibase changelogs and Flyway migrations, DTOs and MapStruct mappers and even more!
DTOs can be implemented as POJOs or records. The latter should be preferred since they provide all we need for DTOs: immutability, simplicity, and less boilerplate. For both cases, we need to implement additional mapper classes or use libraries like MapStruct or ModelMapper.
If we use the Spring Data framework and need to limit data on the data access layer, we can use projections as DTOs. Those projections do not require mappers explicitly and can be easily passed between application layers up to the API. Consider dynamic projections if you need to fetch a different number of attributes using the same query.