Hibernate is the most popular ORM framework in Java. Every major update of this framework is a significant event that affects developers who build their applications using Hibernate and businesses which will use applications and spend money on maintenance and migrations.
Introduction
Every Hibernate user has a list of their requirements for the next version. In most cases, it consists of the following (in order of importance):
- Better SQL
- Performance
- Modern JDK support
- Modern RDBMS features support
Hibernate 6 release was about a year ago, but proper adoption always needs to catch up. In JPA Buddy team, we recently introduced Hibernate 6 support and are now ready to share our thoughts about the new version. This article will look at Hibernate 6 both from the outside (new APIs) and the inside (new architecture). Most developers focus on API changes because tools and applications typically deal with them. But internal changes may be even more critical because they:
- Affect the top two points in our list: SQL generation and performance
- Stay within the framework for a long time and provide a base for following new features
Now, Hibernate 6.2 is about to be released, so let’s look at the Hibernate 6.x line a bit closer.
API Changes
We will start with a quick review of the API changes. There are release notes and migration guide for every release, and we’re not going to repeat them in this chapter. We’ll note the most significant changes in the Hibernate 6.
Jakarta Persistence 3.x
Starting from Hibernate 6, we need to use jakarta.persistence.* packages instead of good old javax.persistence.*. And this is a breaking change and a big headache for migration. For most cases, automatic migration tools will help, like the one built into IntelliJ IDEA. You might need more than just a complex code that extensively uses reflection. This is precisely where adequately automated application testing is a good investment.
Another migration we need to do (if we haven’t done it yet) is moving to Java 11. We’d recommend that you migrate to Java 17 because it is the minimal JDK version for Spring Boot 3. Why Spring Boot 3? Because it is the typical software development stack for Java applications: Spring Boot + Spring Data JPA. The 3rd version of Spring Boot uses Hibernate 6 by default and requires JDK 17. So, migration is inevitable.
Attributes mapping update
Here we can see breaking changes too! For a starter, now type description annotations are type-safe. Let’s consider one of the popular tasks: storing JSON in the database column. Some modern databases have a particular datatype for such columns. For Hibernate 5, we could either define our custom type for that or use Vlad Mihalcea’s Hybernate Types library. Let’s have a look at the code for the latter case. For example, we’ll use the spring-petclinic application. For this application, we’ll extend the Visit entity, add a Recipe to it, and store it as a JSON object in the database.
public class Recipe {
private String diagnosis;
private String recommendation;
//Getters and setters omitted
}
For Hibernate 5, the Visit entity will look like this:
@Entity
@Table(name = "visits")
public class Visit extends BaseEntity {
//Some attributes omitted
@Column(name = "recipe")
@Type(type = "com.vladmihalcea.hibernate.type.json.JsonType")
private Recipe recipe;
}
In Hibernate 6, we don’t need a 3rd party library (though we can) since this version supports JSON out-of-the-box:
@Entity
@Table(name = "visits")
public class Visit extends BaseEntity {
//Some attributes omitted
@Column(name = "recipe")
@JdbcTypeCode(SqlTypes.JSON)
private Recipe recipe;
}
Note that in the code above, we use constants but not strings. So, fewer errors and better auto-completion in IDEs.
Better date storage
Storing dates and times in the database looks like an easy task. For those who have yet to try it for applications that work in different time zones. Some databases introduced a new datatype for that: timestamp with timezone. And now, Hibernate 6 can use this feature. It introduces a new annotation: @TimeZoneStorage, which instructs ORM to use this column datatype when generating DDL for the table. What is excellent, there is an option for databases that do not have a timestamp with timezone datatype! Now we can store the time zone in a separate column, and Hibernate will properly store java date and time using two columns: timestamp and timezone. Entity attribute definition looks like this:
@Entity
@Table(name = "pet")
public class Pet {
@Column(name = "name")
private String name;
@Column(name = "birth_date")
@TimeZoneStorage
private ZonedDateTime birthDate;
…
}
By default, Hibernate uses the native RDBMS data type to store the date with its timezone. If such data type is not supported, Hibernate creates an additional column with the _tz suffix. There are more options:
- Normalize the date according to the DB server timezone
- Normalize the date to UTC timezone
- Force Hibernate to use a column to store timezone
So, with Hibernate 6, we will have less pain with dates.
ID generation changes
In Hibernate 6, ID generation has changed significantly, and this might affect those who plan to migrate to this version.
Sequence naming
If an application uses sequences to generate primary key values, insert statements may not work for some cases. Let’s consider the following code:
@Entity
@Table(name = "visits")
public class Visit {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Integer id;
}
What is the default sequence name for the ID generation query? The correct answer is: “It depends on naming generation strategy”. Hibernate 6 provides three strategies for compatibility:
- SingleNamingStrategy (Hibernate version < 5.3)
- LegacyNamingStrategy
- StandardNamingStrategy (Hibernate version >= 6.0)
By default, Hibernate 6 uses modern StandardNamingStrategy. According to this strategy, the sequence name will be visits_seq, but not hibernate_sequence as for the previous two strategies. So, if we use default sequence names for entities and plan to migrate to the latest Hibernate, we need to specify the sequence naming strategy explicitly:
hibernate.id.db_structure_naming_strategy=single/legacy/standard
New UUID generation approach
UUID is a prevalent format for client-generated primary keys. In the previous version, the UUID generator was implicit. Hibernate detected the ID field type and used UUID random generator automatically. In Hibernate 6, this feature was made a bit more explicit. Now it is recommended to define UUID primary key in the following way:
@Id
@UuidGenerator(style = UuidGenerator.Style.TIME)
@GeneratedValue
private UUID id;
We explicitly define the generator and UUID generation style. It is the feature that uses different algorithms for UUID generation:
- Auto/Random – default strategy that uses the
UUID.randomUUID()method. - Time – time-based generation strategy consistent with IETF RFC 4122. Uses an IP address rather than a mac address. This strategy may be slower than the previous one.
So, in Hibernate 6, client-based ID generation syntax becomes uniform with server-based one.
Subtle change in composite IDs
Composite primary keys are not the easiest part in Hibernate, but they are not uncommon. Let’s consider the following entity:
@Entity
@Table(name = "collar")
public class Collar {
@EmbeddedId
private CollarId collarId;
@Column(name = "collar_message")
private String collarMessage;
…
}
And here is the definition of the composite primary key class:
@Embeddable
public class CollarId {
@Column(nullable = false)
private Long serialId;
@OneToOne(optional = false)
@JoinColumn(name = "pet_id", nullable = false)
private Pet pet;
…
}
As a Hibernate 5 user, can you spot the problem in the PK class definition? Yes, Hibernate 6 does not require PK classes to implement Serializable. Not a vast improvement, but less code to write and fewer rules to remember.
Long text store improvements
If we need to store long text in the database, we could meet some unexpected issues. For example, PostgreSQL might have problems with transactions and searches using the like operator.
Hibernate 6 unifies long text field definition using the @JdbcTypeCode annotation.
@JdbcTypeCode(SqlTypes.LONGVARCHAR)
@Column(name = "description")
private String description;
Using this approach, we will get up to 32K text stored in the database column. If we need to store larger amounts, we can define the field like this:
@Column(name = "doc_txt", length = Length.LOB_DEFAULT)
private String docText;
It will give us about 1Gb of text. We should use the @Lob annotation if we need more. This will create DB-specific LOB storage for your text, and we’ll need to consider all limitations connected to this approach mentioned at the beginning of the section.
Better multitenancy
Multitenancy allows one application instance for different clients to use different datasets. Many big players (Salesforce, WorkDay, Sumo Logic, etc.) use this approach. Implementation can be different:
- Shared schema. Data for different clients is stored in a single table. Applications use a unique “discriminator” column to fetch data for a particular client.
- Shared database, different schemas.
- Different databases.
The latter two approaches are self-explaining and require re-connecting to DB, depending on the client.
In Hibernate 6, the “shared schema” approach was implemented properly. Let’s have a look at the following entity code:
@Entity
@Table(name = "owner")
public class Owner {
@Id
@GeneratedValue
@Column(name = "id", nullable = false)
private Long id;
@Column(name = "name")
private String name;
@TenantId
@Column(name = "clinic")
private String clinic;
}
Note the @TenantId annotation. This is the discriminator marker. Hibernate will append the where condition using this field to fetch data for a particular tenant. All we need to do is to implement a resolver to get a tenant string from a request similar to this:
@Component
public class TenantIdentifierResolver implements
CurrentTenantIdentifierResolver, HibernatePropertiesCustomizer {
@Override
public String resolveCurrentTenantIdentifier() {
return …//Fetch identifier from the session, request, etc.;
}
@Override
public void customize(Map<String, Object> hibernateProperties) {
hibernateProperties.put(AvailableSettings.MULTI_TENANT_IDENTIFIER_RESOLVER, this);
}
}
If we decide to use the “shared schema” approach for multi-tenancy, we need to remember that the where condition will not apply for:
- Native SQL queries
- Entities fetched using the
@OneToManyassociation
Other than that, the new multi-tenancy API works like a charm.
Conclusion: API changes
As we can see, Hibernate 6 introduces modern JDK support and better data mapping for modern RDBMSes. Besides, its API has become cleaner, more concise, and type-safe. Fewer strings, more enums, and named constants in annotation parameters will lead to fewer typos issues, hence runtime errors.
We’ve described just some changes introduced in Hibernate 6: those that looked interesting to us. To find more information, please refer to release notes.
Now let’s look at the most exciting part: internal changes in the framework.
Internal changes
Framework internals affect the most interesting areas of the ORM: better SQL and performance. Developers can be OK with the ugly API if a product provides excellent performance (though Hibernate 6 has a nice API). This section will review significant Hibernate 6 internal architecture changes and see why they matter.
Read-by-position
The first big change in Hibernate 6 – read data from rows in JDBC result set by a column position instead of name. The usual result set can be represented as a table with headers named by select column aliases. During data load, Hibernate reads data, creates an entity instance for every row, and fills it with data. In the previous versions, Hibernate generated aliases for every column and used those aliases to fill property values in entity instances.
select
vet0_.id as id1_5_,
vet0_.first_name as first_na2_5_,
vet0_.last_name as last_nam3_5_
from vets vet0_
Starting from Hibernate 6, the framework reads data by the column position, not by its name. This implementation has the following advantages:
- Deserialization is faster
- Cleaner and smaller SQL strings
- Less joins for joined inheritance and secondary tables
Now, SQL for the same query looks like this:
select
v1_0.id,
v1_0.first_name,
v1_0.last_name
from vets v1_0
It’s much better, isn’t it?
Semantic Query Model
The semantic query model (SQM) is the most significant and crucial change in Hibernate framework, boosting its evolution for the following years.
The main idea behind SQM is to provide a uniform internal representation for both Criteria API and HQL and perform SQL generation based on this representation. In previous Hibernate versions, Criteria API calls were translated to HQL, and then HQL strings were transformed to SQL. It was excessive work that also included string manipulation. It took much work to support and evolve.
Starting from Hibernate 6, both Criteria API calls and HQL statements are translated into SQM. Then Hibernate generated SQL based on this data structure. While implementing this feature, Hibernate team also made two big changes:
- Instead of ANTLR2, Hibernate now utilizes ANTLR4 parser. The new version provides more features and has a better API. You can find more information in the great migration guide here.
- Hibernate criteria API is deprecated; JPA Criteria API is used instead.
Let’s look closely at SQM and how it affects SQL generation in Hibernate.
SQM for HQL and Criteria API comparison
Assume that we have a Spring Data JPA repository with the following method:
@Query("SELECT DISTINCT owner FROM Owner owner LEFT JOIN owner.pets WHERE owner.lastName LIKE :lastName% ")
Page<Owner> findByLastName(@Param("lastName") String lastName, Pageable pageable);
If we enable SQL logging in our application, we’ll see the following SQL:
select distinct o1_0.id,o1_0.address,o1_0.city,o1_0.first_name,o1_0.last_name,o1_0.telephone
from owners o1_0
left join pets p1_0 on o1_0.id=p1_0.owner_id
where o1_0.last_name like ? escape ’’
offset ? rows fetch first ? rows only
Now, we can have a look at the semantic query model for the JPQL:
-> [select]
-> [query-spec]
-> [select]
-> [selection]
<- [selection]
<- [select]
-> [from]
-> [root] - `org.springframework.samples.petclinic.owner.Owner(owner)`
-> [joins]
-> [attribute] - `org.springframework.samples.petclinic.owner.Owner(owner).pets(472975650239291)`
[fetched = false]
<- [attribute] - `org.springframework.samples.petclinic.owner.Owner(owner).pets(472975650239291)`
<- [joins]
<- [root] - `org.springframework.samples.petclinic.owner.Owner(owner)`
<- [from]
-> [where]
-> [is-like]
:lastName
-> [basic-path] - `org.springframework.samples.petclinic.owner.Owner(owner).lastName`
<- [is-like]
<- [where]
<- [query-spec]
<- [select]
We can see the query root entity and attributes selected using the join clause. Based on this tree structure, Hibernate generated the SQL we could see before. Let’s have a look at the SQL generated for the same Criteria API query and compare SQMs.
Just a reminder: Criteria API in Hibernate 6 is now based on Jakarta specification, not Hibernate. It is verbose but provides better type safety. To perform the same query as before, we need to write the following code:
public List<Owner> findByLastNameCriteria(String lastName) {
Session session = em.unwrap(Session.class);
CriteriaBuilder cb = session.getCriteriaBuilder();
CriteriaQuery<Owner> query = cb.createQuery(Owner.class);
Root<Owner> ownerRoot = query.from(Owner.class);
ownerRoot.join("pets", JoinType.LEFT);
query.select(ownerRoot).distinct(true).where(cb.like( ownerRoot.get("lastName"), lastName));
Query<Owner> ownerQuery = session.createQuery(query);
return ownerQuery.getResultList();
}
The generated SQL will look like this:
select distinct o1_0.id,o1_0.address,o1_0.city,o1_0.first_name,o1_0.last_name,o1_0.telephone
from owners o1_0
left join pets p1_0 on o1_0.id=p1_0.owner_id
where o1_0.last_name like ? escape ''
It looks like the one generated for HQL, the only difference in the pagination clause for the first example. Now let’s look at the SQM:
-> [query-spec]
-> [select(distinct)]
-> [selection]
…
<- [selection]
<- [select(distinct)]
-> [from]
-> [root] - `org.springframework.samples.petclinic.owner.Owner(484076037736583)`
-> [joins]
-> [attribute] - `org.springframework.samples.petclinic.owner.Owner(484076037736583).pets(484076037783791)`
[fetched = false]
<- [attribute] - `org.springframework.samples.petclinic.owner.Owner(484076037736583).pets(484076037783791)`
<- [joins]
<- [root] - `org.springframework.samples.petclinic.owner.Owner(484076037736583)`
<- [from]
-> [where]
-> [is-like]
-> [basic-path] - `org.springframework.samples.petclinic.owner.Owner(484076037736583).lastName`
<- [is-like]
<- [where]
<- [query-spec]
As we can see, SQM is also the same. The only difference is in the LIKE clause representation.
SQL Generation internals
What is behind this generation's magic? In the first stage, SQM generation happens. To parse HQL and build SQM, Hibernate uses ANTLR. For Criteria API, no parsing is required. In fact, we build an SQM tree while creating a Criteria API query. If we look at the code, we’ll see that we define root, joins, etc., programmatically for the SQM tree. After SQM is created, the following classes come into play:
- SemanticQueryWalker – walks through the SQM tree and generates a so-called “standard” or “generic” SQL statement generation model for the given SQM.
- SqlAstTranslator – translates the “standard” SQL into dialect-specific SQL based on Hibernate settings.
During the translation, the SqlAstTranslator class uses function rendering classes to generate SQL for standard SQL functions, including analytics functions.
- FunctionRenderingSupport
- AbstractSqmSelfRenderingFunctionDescriptor
The latter is the superclass for various renderers, which implement generation for a particular SQL fragment connected with a function.
- AvgFunction
- ListaggFunction
- etc.
The SQM to SQL generation can be represented using the following diagram:
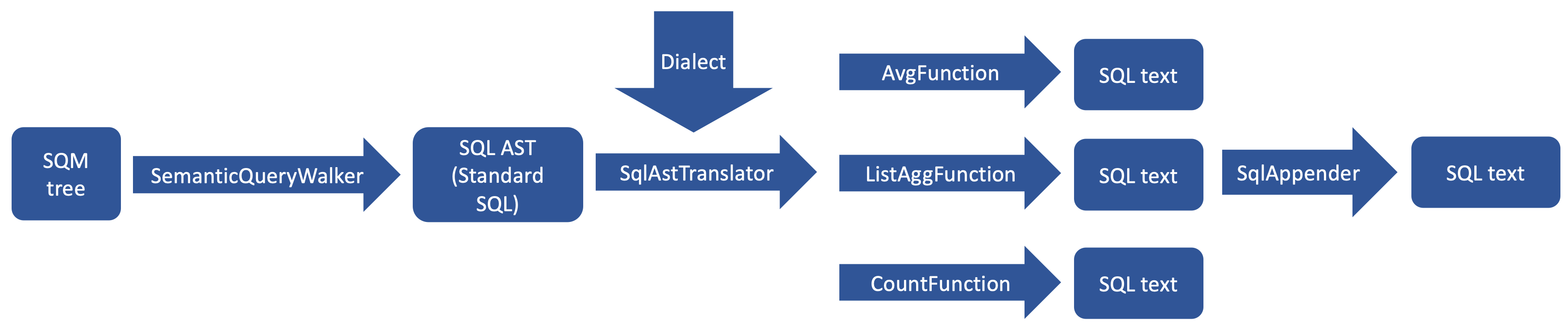
Obviously, we won’t be able to avoid string manipulations when generating SQL, but now it is encapsulated in a corresponding renderer. The following example shows some code for generating the avg() function:
public class AvgFunction extends AbstractSqmSelfRenderingFunctionDescriptor {
…
public void render(
SqlAppender sqlAppender,
List<? extends SqlAstNode> sqlAstArguments,
Predicate filter,
SqlAstTranslator<?> translator) {
sqlAppender.appendSql( "avg(" );
final Expression arg;
if ( sqlAstArguments.get( 0 ) instanceof Distinct ) {
sqlAppender.appendSql( "distinct " );
arg = ( (Distinct) sqlAstArguments.get( 0 ) ).getExpression();
}
else {
arg = (Expression) sqlAstArguments.get( 0 );
}
…
The beauty of this solution is in its extensibility. Renderers implement a standard Java interface, so developers can directly implement their function renderer and use custom functions in HQL. As of today (Hibernate 6.2.0.CR2), there is no complete tutorial on extending Hibernate, but here is the short list of classes that are involved in this process:
SqmFunctionRegistry- we should add new function definitions into this classFunctionContributor- SPI for functionsSqmFunctionDescriptor- should be implemented for SQL generation for a custom function similar toAvgFunction,ListaggFunctionetc.
The Hibernate team will obviously continue extending HQL with functionality specific to modern SQL standards. It is well-known that JPQL/HQL capabilities are not the same as SQL. It is why developers often use native SQL or even move towards other solutions like jOOQ. With the new architecture introduced in Hibernate 6, the gap between HQL and SQL will be smaller or even disappear in future versions. While preparing the article, we got the news about MERGE SQL operator support. It was less than a month from the previous release which didn’t support it. Hibernate is evolving faster than before thanks to SQM.
Analytic functions in Hibernate
You could notice the ListAggFunction class in the function renderers list. Yes, it is not a mistake; Hibernate supports some analytics and window functions too! It was even ported back to JPQL partially, and we hope that JPQL will continue extending. Let’s look at how to write an analytic function in HQL. For the Petclinic example, let’s find an average age for each type of pet. Pet entity structure:
@Entity
@Table(name = "pets")
public class Pet extends NamedEntity {
@Id
private Integer id;
@Column(name = "name")
private String name;
@Column(name = "birth_date")
private LocalDate birthDate;
@ManyToOne
@JoinColumn(name = "type_id")
private PetType type;
//…
}
The handwritten SQL for this query and table structure in the PostgreSQL database will look like this:
select id, name, type_id,
(extract(year from now()) - extract (year from birth_date)) as age,
avg(extract(year from now()) - extract (year from birth_date))
over (partition by type_id) as avg_age
from pets
In HQL, it will look like this:
select p.id, p.name, p.type,
(year(current_date) - year(p.birthDate)) as age,
avg(year(current_date) - year(p.birthDate)) over (partition by p.type) as avg_age
from Pet p
So, what will Hibernate generate? Here is SQL generated by Hibernate for the HQL query written above:
select p1_0.id,p1_0.name,t1_0.id,t1_0.name,
(extract(year from current_date)-extract(year from p1_0.birth_date)),
avg((extract(year from current_date)-extract(year from p1_0.birth_date)))
over(partition by p1_0.type_id)
from pets p1_0
join types t1_0
on t1_0.id=p1_0.type_id
We can see that Hibernate correctly used the extract() and over() functions and the partition clause. The query is almost the same as the hand-written one. The only difference is an additional join. It can be explained by the *ToOne association nature – it is eager by default, so Hibernate fetches pet type data along with the pet’s data.
We must mention that HQL provides better analytics function support than JPQL and even Hibernate’s own Criteria API. For example, window functions in Criteria API were introduced starting from Hibernate 6.2 only. The following analytic functions are supported in Criteria API:
- Ordered set-aggregate functions:
listagg,mode,percentile_cont,percentile_disc - Window functions:
row_number,first_value,last_value,nth_value,dense_rank,rank,percent_rank,cume_dist
More information about HQL can be found in the documentation.
Entity graph traversal changes
To generate a query, Hibernate needs to traverse the entity graph and determine which entities should be included in the statement. During this traversal, it also tries to detect circular references. As it said in the documentation: “As back-ground, Hibernate does understand whether a fetch is actually, truly circular. It simply understands that while walking a fetch-graph, it encounters the same table/column(s) making up a particular foreign key. In this case, it simply stops walking the graph any deeper”.
We can traverse through entities using depth-first or width-first approaches. Hibernate 6 uses width-first in contrast to previous versions that used depth-first. This may affect query generation, which can be surprising for experienced Hibernate developers. Let’s consider the following entity:
public class Pet {
@Id
@Column(name = "id", nullable = false)
private Long id;
@Column(name = "name")
private String name;
@ManyToOne
@JoinColumn(name = "parent_1_id")
private Pet parent1;
@ManyToOne
@JoinColumn(name = "parent_2_id")
private Pet parent2;
}
For this entity, let’s execute a simple query:
Pet pet = petRepository.findById(1L);
Now it is time to look at the generated SQL, especially at join clauses. For Hibernate 5, it will be the following:
select
…
from
pet pet0_
left outer join
pet pet1_
on pet0_.parent_1_id=pet1_.id
left outer join
pet pet2_
on pet1_.parent_2_id=pet2_.id
where
pet0_.id=?
Looks OK. It is a straightforward query with no surprises. Now let’s have a look at the SQL generated by Hibernate 6:
select
…
from
pet p1_0
left join
pet p2_0
on p2_0.id=p1_0.parent_1_id
left join
pet p3_0
on p3_0.id=p2_0.parent_2_id
left join
pet p4_0
on p4_0.id=p1_0.parent_2_id
left join
pet p5_0
on p5_0.id=p4_0.parent_1_id
where
p1_0.id=?
We have four join’s here! For three recursive associations, there will be 15 join’s. This is how Hibernate developers explain this: “as you can see, this leads to a lot of joins very quickly, but the behavior of 5.x simply was not intuitive. To avoid creating so many joins, and also in general, we recommend that you use lazy fetching i.e. @ManyToOne(fetch = FetchType.LAZY) or @OneToOne(fetch = FetchType.LAZY) for most associations, but this is especially important if you have multiple self-referencing associations as you can see in the example”.
In the sixth version, Hibernate combines all possible joins and foreign keys in the query and stops only when it sees that the reference is circular. It becomes clear is we look at the example with three recursive associations:
FROM Node
JOIN Node.node1
JOIN Node.node1.node2
JOIN Node.node1.node2.node3
JOIN Node.node1.node3
JOIN Node.node1.node3.node2
JOIN Node.node2
JOIN Node.node2.node1
JOIN Node.node2.node1.node3
JOIN Node.node2.node3
JOIN Node.node2.node3.node1
JOIN Node.node3
JOIN Node.node3.node1
JOIN Node.node3.node1.node2
JOIN Node.node3.node2
JOIN Node.node3.node2.node1
So, in Hibernate 6, prefer the LAZY fetch type to avoid combination explosion for the recursive associations during queries.
Hibernate 6 and Spring Framework
Developers rarely use “pure” Hibernate. Spring Data JPA (part of the Spring Framework ecosystem) is the most popular library for data access. Hibernate 6 is included in Spring Boot framework version 3. So if you plan to migrate to Hibernate 6, you’ll need to move to Java 17 – the minimum version supported by Spring Boot 3.
In the current version (3.0.1), Spring Data JPA does not support window functions in derived methods. There is a big chance that it won’t happen soon. It would be hard to write a method name in the Spring Data JPA repository for a query like this:
select p.id, p.name, p.type,
(year(current_date) - year(p.birthDate)) as age,
avg(year(current_date) - year(p.birthDate)) over (partition by p.type) as avg_age
from Pet p
With Hibernate 6, you can use HQL for complex queries in Spring Boot 3 using Spring Data JPA library using @Query annotations. In contrast to native SQL queries, it is validated during boot-time, so there is less chance of getting a runtime error in the working application.
Using Spring Data JPA, Hibernate or EclipseLink and code in IntelliJ IDEA? Make sure you are ultimately productive with the JPA Buddy plugin!
It will always give you a valuable hint and even generate the desired piece of code for you: JPA entities and Spring Data repositories, Liquibase changelogs and Flyway migrations, DTOs and MapStruct mappers and even more!
Conclusion
Hibernate 6 is a big step forward compared to previous versions. It supports modern JDK and Jakarta specifications for data access. The ORM provides better API for developers: better date and time processing, more straightforward custom datatype transformers development, built-in JSON support, etc.
The most significant thing is its new internal architecture. Thanks to SQM and modular structure, we can enjoy better SQL generation, faster data-to-object mapping, and support for modern SQL standards. And these changes provide a solid base for faster development for future versions.