Intro
“JPA is slow, complex, and brings too much pain”. We can hear this often here and there. This “common opinion” makes architects consider migration from JPA to other technologies, even for the existing projects. The main complaints about JPA are:
- Lack of control over generated SQL queries
- Memory consumption due to L1 cache
- Hard to create complex queries with JPQL/HQL
- Hard to map complex query results to arbitrary classes
JPA is a specification, not a framework. So, when people say “JPA,” they usually mean a particular framework: Hibernate –the most popular JPA implementation in the world. Developers typically use Hibernate in conjunction with Spring, namely Spring Data JPA. This framework provides a set of high-level abstractions over JPA/Hibernate to simplify application development. So, if we decide to replace JPA with another data access framework, we usually need to replace Spring Data JPA too. The perfect replacement should be seamless – require a minimum amount of work, and resolve the JPA issues mentioned earlier. We can consider two libraries:
- JDBC Template
- Spring Data JDBC
We omit pure JDBC in the consideration. This framework gives total control over queries but is too low-level. Therefore, efforts in writing and maintaining the code written with JDBC will outweigh all gains.
Out of the two candidates, the Spring Data JDBC looks like a promising one. Spring Data JPA and Spring Data JDBC use Spring Data Commons as a base library. Both share the same abstractions; the most important one is Repository. In Spring Data JPA, repositories allow us to use derived methods instead of queries. Such methods transparently convert their invocations to queries using a JPA implementation. In Spring Data JDBC, method invocations are transformed into pure SQL and executed via JDBC. Hence, we can hope we won’t need to rewrite the data access layer entirely if we use Spring Data Repositories everywhere in our code. In the ideal world, all we need to do is to change Spring Data JPA dependency to Spring Data JDBC in the build file.
Let’s see whether our assumptions are correct and what issues will arise during migration. We’ll use the “Spring Petclinic” application as an example.
Migration planning
Every framework consists of two parts: APIs and ideas. APIs affect our code directly; we can use only classes provided in the framework. And ideas, though implicit, affect the way we implement the application in general.
Spring Data JDBC is very similar to Spring Data JPA in terms of API. However, JPA provides several useful features that are not present in Spring Data JDBC:
- @*ToOne associations allow us to create bidirectional references between entities.
- Automatic ID generation prevents us from manually selecting IDs from sequences or caring about IDENTITY datatype support in an RDBMS.
- Cascade operations let us deal with related data automatically. Though it requires some carefulness, this feature may be helpful in some cases.
- Batch operations. Hibernate groups similar operations into batches automatically. It helps when an application deals with massive insert operations.
- L1 Cache keeps entities used in one transaction in memory. It allows us not to fetch the same data twice in two services if executed in the same transaction.
- Boot-time query validation identifies issues in derived method names, and JPQL queries at boot-time, thus preventing errors at an early stage.
When we start the migration, we will need to review all places where we use this functionality and replace it with other solutions or re-implement it.
As for the ideas, it is a bit more complex. Spring Data JDBC is built with domain-driven design principles in mind. In the documentation It is stated: “All Spring Data modules are inspired by the concepts of “repository”, “aggregate”, and “aggregate root” from Domain Driven Design. These are possibly even more important for Spring Data JDBC because they are, to some extent, contrary to normal practice when working with relational databases.”
In contrast, JPA data models are usually designed as entity graphs. According to this concept, we can get almost any entity from the application data model by following the entities' associations. JPA is ideal for entity graph traversing. When we use JPA, it is a common practice to pass one entity between various services in the same transaction, process the data, and fetch related entities if a particular service needs them. This approach won’t work for Spring Data JDBC. So, the first thing to do before migrating from Spring Data JPA is to review the data model to define aggregates and aggregate roots explicitly.
To define aggregate, we need to answer a question: “What is an aggregate?”. According to Martin Fowler: “A DDD aggregate is a cluster of domain objects that can be treated as a single unit. An example may be an order and its line items, these will be separate objects, but it's useful to treat the order (together with its line items) as a single aggregate.” We can rephrase it and say: “an aggregate is a composition unit consistent within one transaction.”
Let’s have a look at the PetClinic application data model. For simplicity’s sake, we will use only some entities: Owner, Pet, and Visit. We do not include type – it is a different domain.
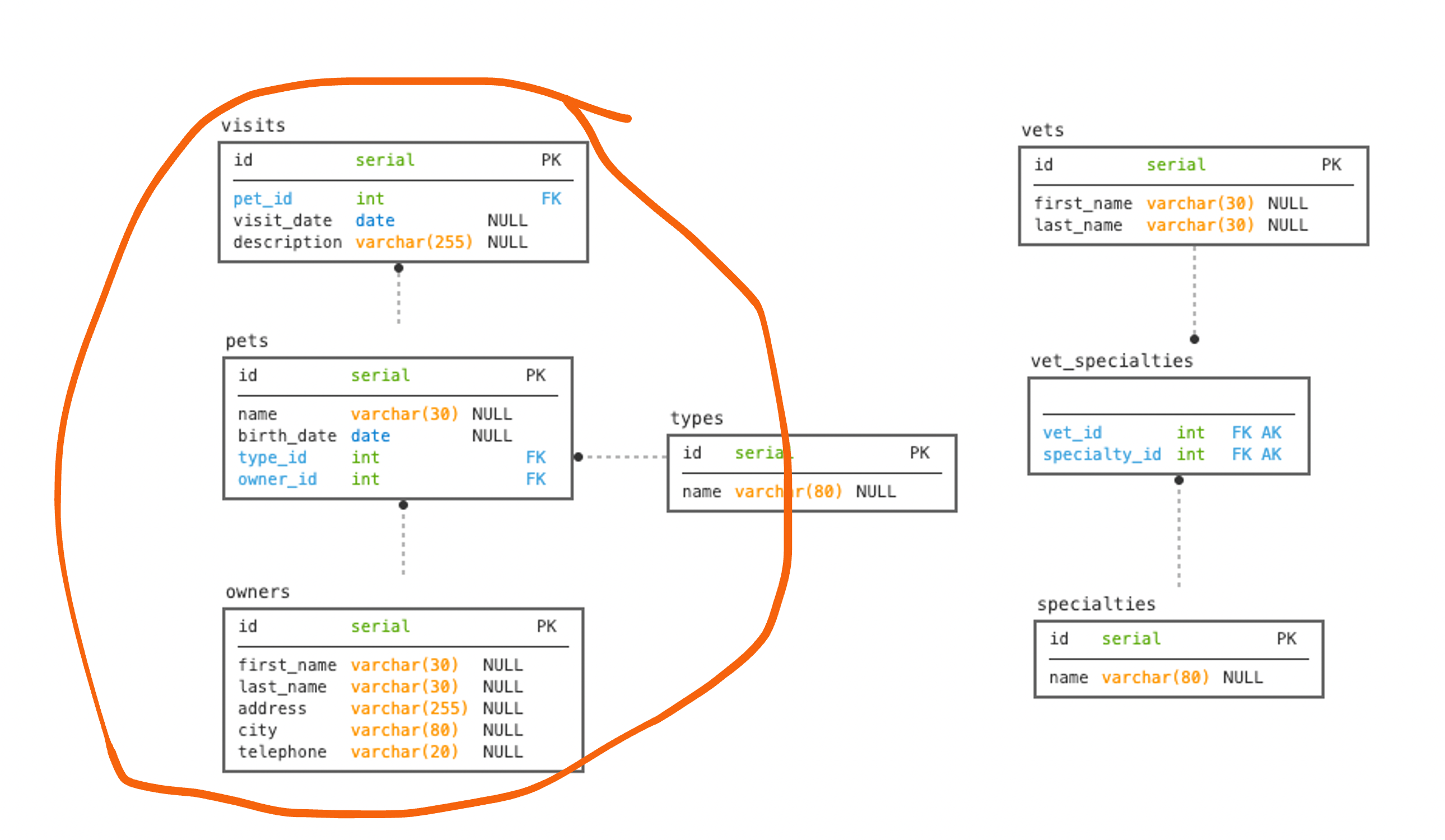
Note the relation between these entities:
- Owner to Pet – One-to-Many
- Pet to Visit – One-to-Many
The problem with defining aggregates is their size. An aggregate should not be too big (tens of entities) or too small (one entity). Even for those entities, we can define different aggregates. The one consisting of all three entities:
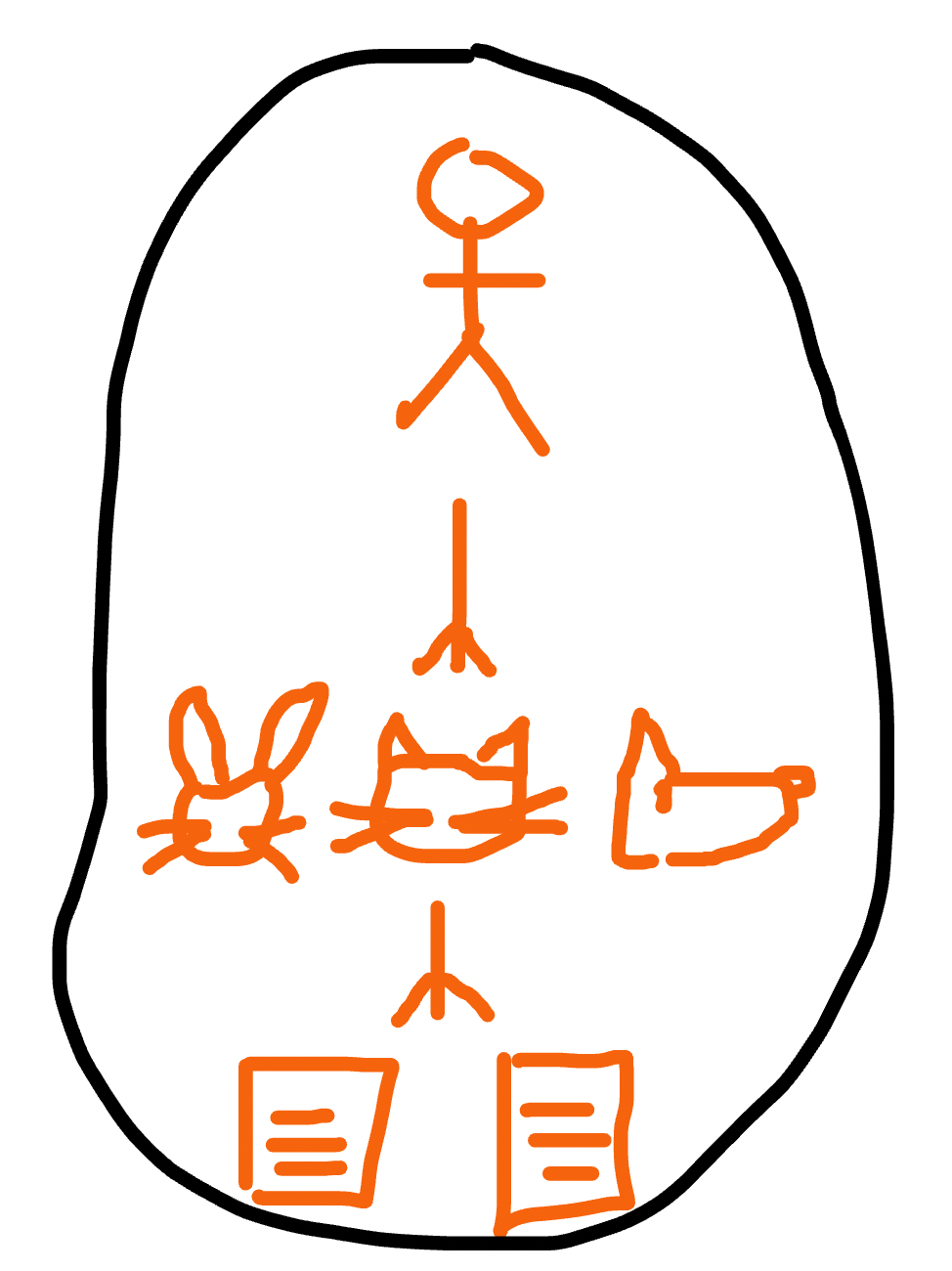
Or two aggregates: Owners and Pets with their visits:
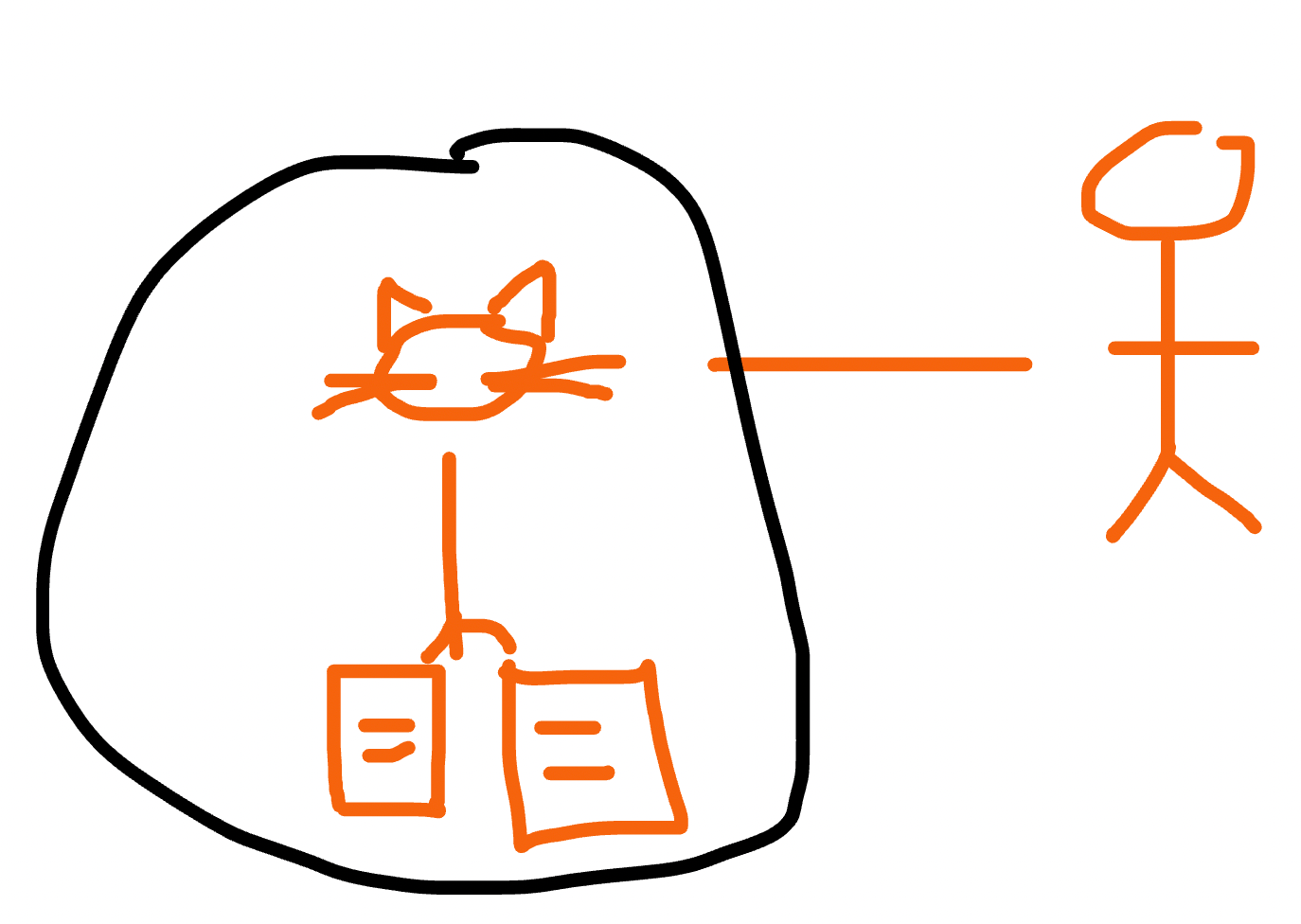
Depending on business requirements, we can choose one option or another. Again, for our example, let’s consider that a Pet can exist without an Owner. So, we’ll use the “Pet+Visit” aggregate.
Why are aggregates important? There are some pure technical things that we should consider:
- All entities in an aggregate should always be eagerly fetched. In our example, we should always fetch Pets with their Visits.
- We should not fetch a single entity if an aggregate contains more. E.g., we cannot fetch either Pet or Visit separately.
- There should be no other single entities attached to the aggregate root – only references. So, the Pet should not have the “Owner” field, just the “OwnerID” reference. “Pet Type” should be a reference too.
- There is a rule: one repository per aggregate root. For our example, there should be no “VisitRepository” in the codebase but “PetRepository” only.
Later we’ll see how it can affect the application.
Make it run, make it right…
If we decide to change one of the cornerstone frameworks in our applications, we will inevitably get compilation errors. When we fix all of them, our application will compile, but it doesn’t mean the absence of errors. The app may not start or, even worse, will fail in runtime. In the following chapters, we will look at some issues that may appear in your application during the migration process.
It doesn’t compile
Spring Data JDBC API is like Spring Data JPA, but still, it is a different framework. First, we need to review our data model and adjust it according to Spring Data JDBC API. Let’s have a look at the code diff below.
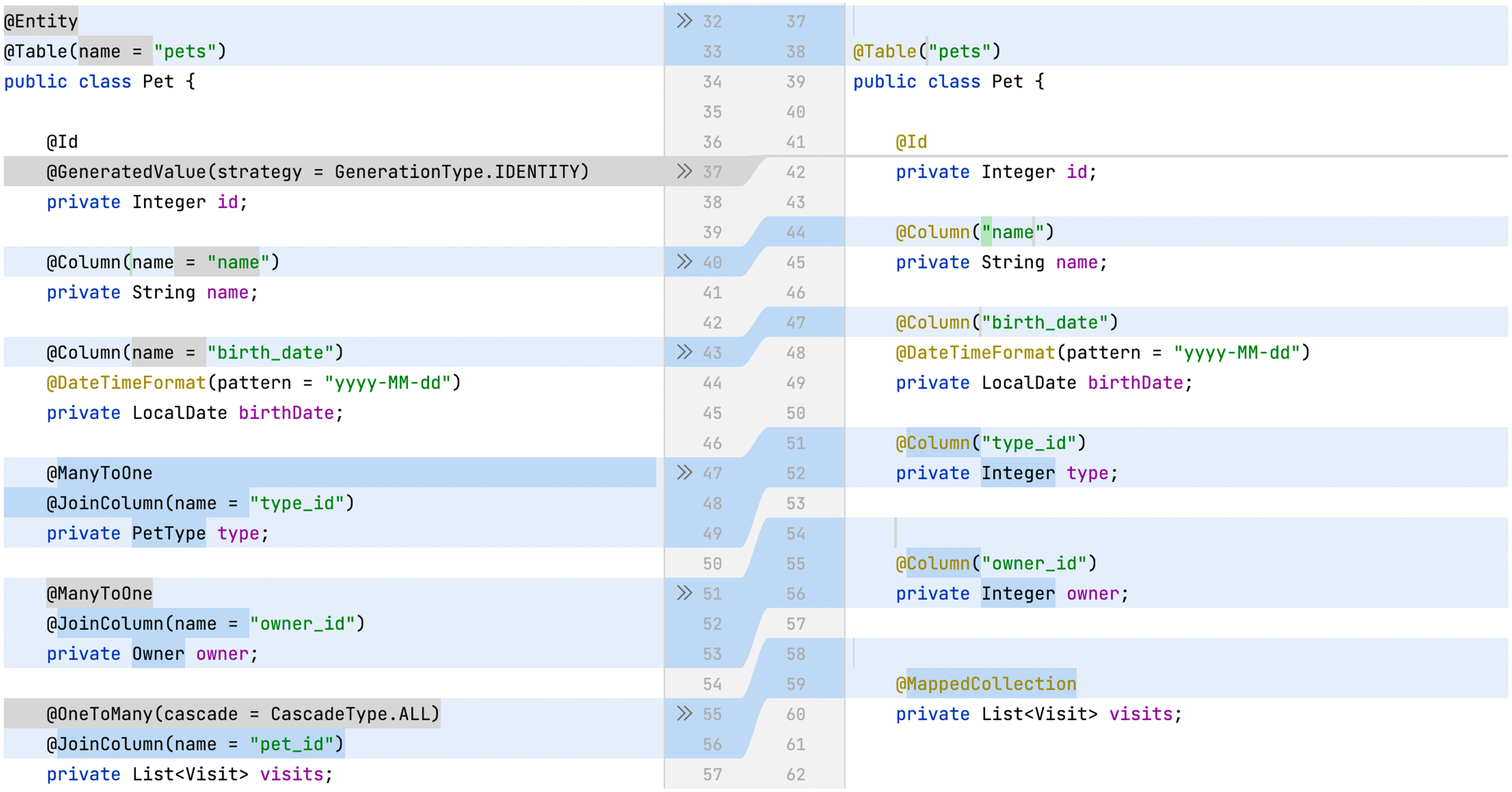
Apart from minor changes like the @Entity removal or the name attribute vanishing, we can see more serious changes.
Associations and SQL
The first big difference is associations change:
OwnerandTypeattributes are just IDs now, not entities- In our case, we cannot manage cascade behavior for *ToMany associations for the
Visitscollection.
It means the following:
- To fetch
OwnerorTypefor a pet, we’ll need to issue one moreselectstatement. If we have a business logic that works with thePetentity, its type, and its owner, we will need to write two additionalselectstatements instead of executing oneselectwithjoinsin JPA. - Spring Data JDBC will always fetch visits for every
Petobject in a separateselectstatement. It looks likeN+1 selectis a natural behavior for Spring Data JDBC.
Conclusion: migration to Spring Data JDBC does not mean less SQL. We’ll need to review all SQL statements and all optimizations made for the JPA-based data access layer and adjust them accordingly.
ID Generation
The next noticeable change is the @GeneratedValue annotation disappearance. What are the consequences of this? Spring Data JDBC supports the ‘identity’ column data type only. So, if we want to use a DB sequence, we’ll need to write a BeforeConvert event listener, according to the documentation. In the code, it will look like this:
@Bean
public ApplicationListener<?> idSetting() {
return (ApplicationListener<BeforeConvertEvent>) event -> {
if (event.getEntity() instanceof Pet) {
setId((Pet) event.getEntity());
}
};
}
The setId method should contain a code to select a value from the sequence and assign it to the id field. So, we have complete control over ID generation, but we’ll have to implement it manually, including ID cache optimization available in Hibernate (if needed).
In contrast to Spring Data JPA, the Spring Data JDBC does not track entity state. So, we cannot initialize the ID field on an entity instantiation. If we do, Spring Data JDBC will try to execute an update statement instead of an insert for a newly created entity instance.
Conclusion: After migrating to Spring Data JDBC, we need to manually implement an ID generation code unless we use an identity column as a primary key. It gives us more flexibility but requires more code to support both java and SQL.
Data Conversion
If we have non-standard data types in our JPA entities, we need custom data converters for them. For Spring Data JDBC, we’ll need to reimplement those converters and re-register them in the application. For example, conversion from Java boolean to SQL char for JPA will look like this:
@Converter(autoApply = true)
public class BoolToChar implements AttributeConverter<Boolean, String> {
@Override
public String convertToDatabaseColumn(Boolean aBoolean) {
return aBoolean != null && aBoolean ? "T" : "F";
}
@Override
public Boolean convertToEntityAttribute(String string) {
return string.equals("T");
}
}
This converter should be split into two classes and registered in a configuration class as per documentation:
@WritingConverter
public class BooleanToStringConverter implements Converter<Boolean, String> {
@Override
public String convert(Boolean aBoolean) {
return aBoolean != null && aBoolean ? "T" : "F";
}
}
@ReadingConverter
public class StringToBooleanConverter implements Converter<String, Boolean> {
@Override
public Boolean convert(String string) {
return string != null && string.equalsIgnoreCase("T") ? Boolean.TRUE : Boolean.FALSE;
}
}
Conclusion: we’ll need to reimplement all custom JPA converters to migrate to Spring Data JDBC. Simple, though, it is still additional work.
It doesn’t start
OK, we’ve fixed the code, and now our application compiles without errors. What can prevent it from starting? Just a couple of things.
Derived methods in repositories
The derived method is a cornerstone abstraction in the Spring Data framework family. By writing a method name in a repository, we can execute a query to a database. For example, in our Petclinic application, we can have the following method:
List<Owner> findByPets_NameLike (String name);
This method will search for owners by their pet’s name. Convenient, isn’t it? Unfortunately, in Spring Data JDBC, such queries won’t work. So, we can search for owners only using their attributes but not nested entities. The JdbcQueryCreator class explicitly limits this:
if (!path.getParentPath().isEmbedded() && path.getLength() > 1) {
throw new IllegalArgumentException(
String.format("Cannot query by nested property: %s",
path.getRequiredPersistentPropertyPath().toDotPath()));
}
So, if we have derived query methods like this, we’ll need to rewrite them using @Query annotation and pure SQL:
@Query("select * from owners o join
pets p on o. id = p.owner_id and p.name like :name")
List<Owner> findByPets_NameLike (@Param("name") String name);
Conclusion: we need to be careful with derived methods. Nested properties are not supported yet, so we’ll need to review and reimplement all such methods using SQL. It may lead to another bump, described in the next section.
All queries are pure SQL
JPQL is not supported in Spring Data JDBC, so we’ll need to rewrite all queries using SQL. Rewriting JPQL to SQL is usually a no-brainer, but in the case of Spring Data JDBC, it is not that simple. Let’s take a look at the following repository method:
@Query("SELECT DISTINCT owner FROM Owner owner
left join owner.pets WHERE owner.lastName LIKE :lastName% ")
Page<Owner> findByLastName(@Param("lastName") String lastName,
Pageable pageable);
If we rewrite the query to SQL, we will get the following method:
@Query("SELECT * FROM owners WHERE last_name LIKE concat(:lastName, ‘%’)")
Page<Owner> findByLastName(@Param("lastName") String lastName,
Pageable pageable);
… the application won’t start! The reason is hidden in the StringBasedJdbcQuery class code:
if (queryMethod.isPageQuery()) {
throw new UnsupportedOperationException(
"Page queries are not supported using string-based queries.
Offending method: " + queryMethod);
}
The correct code may look like this:
@Query("SELECT * FROM owners WHERE last_name LIKE concat(:lastName,'%')")
Collection<Owner> findByLastName(@Param("lastName") String lastName);
So, we lost automatic pagination here. The workaround is described in the Spring Data JDBC JIRA . We’ll need to fetch all data and then get a required page.
interface OwnerRepository extends PagingAndSortingRepository<Owner, Long> {
List<Owner> findAllByLastName (String lastName, Pageable pageable);
Long countAllByLastName(String lastName);
}
//In the code:
List<Owner> ownerList = repository.findAllByLastName("...", pageable);
Long ownerTotalCount = repository.countAllByLastName("...");
Page<Owner> ownerPage = PageableExecutionUtils.getPage(ownerList, pageable, () -> ownerTotalCount);
We should consider another thing: SQL queries are not validated at boot time in contrast to JPQL ones. So, if we made a typo in a query, we’ll find out about it only at boot time. That’s not a great thing, but unit testing should help. And this brings us to the issues that cannot be caught by the compiler and boot time validation: runtime errors. We’ll have a look at them in the next section.
Conclusion: just rewriting JPQL to SQL in custom query methods in repositories is not enough. We’ll need either to get rid of pagination or to implement pagination manually in our repositories. Also, SQL queries are not validated during the application startup, so it is a good idea to implement unit tests before rewriting queries from JPQL to SQL.
It doesn’t work
Incorrect application behavior is a nightmare for every developer. The application compiles, starts, and runs successfully, but sometimes the data disappears. Or NPE is thrown. Or deadlock happens. Let’s look at three problems that might occur after Spring Data JPA codebase migration to Spring Data JDBC.
L1 cache – friend or foe?
One of the key differences between Spring Data JPA and Spring Data JDBC – there is no transaction context in Spring Data JDBC. The framework does not track entity state, does not fetch associations lazily on first access, and does not save changes when a transaction is closed. In terms of JPA, Spring Data JDBC always deals with “detached” entities. So, we cannot rely on JPA anymore and need to review the data access layer and our application's business logic.
For example, let’s look at a couple of services that implement the following business logic. If a visit to the veterinarian is postponed, we change its date and provide a discount for it. Two services implement it: VetService to postpone a visit for a particular veterinarian, and VisitService, which provides a discount based on visit ID.
@Service
public class VetService {
@Transactional
public List<Visit> postponeVisitsForVet(Vet vet,
LocalDate fromDate, LocalDate toDate) {
List<Visit> visits = visitRepository.findByDateAndVet(fromDate, vet);
visits.forEach(visit -> {
visit.setDate(toDate);
visitService.applyDiscount(visit.getId(), BigDecimal.TEN);
});
return visits;
}
//
@Service
public class VisitService {
@Transactional
public void applyDiscount(Integer visitId, BigDecimal discount) {
Visit v = visitRepository.findById(visitId);
//Applying discount arithmetics
}
This code will compile, but it won’t work with Spring Data JDBC. First, we do not save visits before returning them from the postponeVisitsForVet method. Second, the discount won’t be applied even if we add this line!
The second issue needs a bit more explanation. Both methods: postponeVisitsForVet and applyDiscount run in the same transaction. In JPA, when we fetch a visit by its ID, the framework will look for its instance in the transaction context (a.k.a. L1 cache) first. So, in JPA, the same visit instance will be used to change the date and apply the discount. In JDBC, we deal with detached objects. So, we will load a new visit instance by ID in the VisitService, apply the discount and save it with the old date but discounted price.
Meanwhile, in the VetService, we have another instance with the new date but the old cost without the discount. After saving it, we overwrite the visit with a discounted price, and that’s it! The discount is lost. We need to change the service API to pass the visit object instead of its ID to fix this.
Conclusion: By removing transaction context (L1 cache), we lose the ability to track an entity state inside a transaction. It may cause data loss, especially when we reload an entity in the same transaction but different code areas. This is a serious problem, and it requires a complete business logic services code review.
Be careful with data update
The absence of the transaction context changes the way Spring Data JDBC performs cascade updates. Let’s have a look at the example. The “Petclinic” application allows us to modify the information about a pet using the following screen:
In the code, the HTTP request handler looks like this:
@PostMapping("/pets/{petId}/edit")
public String processUpdateForm(@Valid Pet pet,
BindingResult result, Owner owner, ModelMap model) {
owner.addPet(pet);
this.petRepository.save(pet);
return "redirect:/owners/{ownerId}";
}
Hibernate generates the following SQL for this:
Hibernate: select * from pets pet0_ where pet0_.id=?
Hibernate: * from owners owner0_ left outer join pets pets1_ on owner0_.id=pets1_.owner_id where owner0_.id=?
Hibernate: select * from types pettype0_ where pettype0_.id=?
Hibernate: select * from types pettype0_ where pettype0_.id=?
Hibernate: update pets set name=?, birth_date=?, owner_id=?, type_id=? where id=?
The log shows the expected set of actions: entity merge and subsequent update of the information about the pet. After migration to Spring Data JDBC, the handler will look like this:
@PostMapping("/pets/{petId}/edit")
public String processUpdateForm(@Valid Pet pet,
BindingResult result, Owner owner, ModelMap model) {
pet.setOwnerId(owner.getId());
this.petRepository.save(pet);
return "redirect:/owners/{ownerId}";
}
If we have a look at the application log file, we’ll see the following:
JdbcTemplate: [SELECT * FROM `owner` WHERE `owner`.`id` = ?]
JdbcTemplate: [select * from pet_type order by name]
JdbcTemplate: [UPDATE `pet` SET `name` = ?, `birth_date` = ?, `type_id` = ?, `owner_id` = ? WHERE `pet`.`id` = ?]
JdbcTemplate: [DELETE FROM `visit` WHERE `visit`.`pet_id` = ?]
It looks like we’ve just deleted all visits from the database! It turns out that we get a pet without its visits from the web UI in the original application code. In its turn, we discover that Spring Data JDBC updates aggregation root entities in a special way. It deletes all child entities and reinserts them into the database. Why is that? The answer is: Spring Data JDBC does not track entity state. There is no entity merge process, so all we can do is recreate the entities if we don’t know their state.
To fix this, we must fetch a pet with all its visits and pass this data to the web UI. The web UI should submit the whole aggregation root to the application (pets and visits). Another option – use smaller aggregates and split pets and visits so that visits will be a different aggregation root. In this case, the “Pet” class won’t contain a collection of visits as a property. For JPA developers, it may look unusual, but it is the price we pay for accepting another framework’s philosophy.
Conclusion: Spring Data JDBC does not track entity states. If an aggregation root has child entities, it will constantly be recreated on an aggregation root update. So, we need to pay extra attention to ensure that we always pass the aggregation root with its children to the repository.
Batch operations
Strictly speaking, it is not an error but a performance impact. In Spring Data JPA with Hibernate, we can set up batch inserts easily by specifying two properties:
spring.jpa.properties.hibernate.jdbc.batch_size=4
spring.jpa.properties.hibernate.order_inserts=true
Spring Data JDBC does not support batch operations yet, so if we want to use them, we’ll need to implement it manually using JdbcTemplate and Spring Data repository extension. First, we need to implement the extension:
public class WithOwnerBatchImpl implements WithOwnerBatch<Owner> {
private final String saveSql = """
insert into owner (id, first_name, last_name, address, city, telephone)
values (?, ?, ?, ?, ?, ?)
""";
@Override
public <S extends Owner> Iterable<S> saveAll(final Iterable<S> entities) {
int[] keys = this.jdbcTemplate.batchUpdate(saveSql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
Owner entity = list.get(i);
ps.setInt(1, //assign ID);
ps.setString(2, entity.getFirstName());
ps.setString(3, entity.getLastName());
//etc
}
});
And then, we can override the standard repository method by adding this extension to the repository declaration:
public interface OwnerRepository extends Repository<Owner, Integer>, WithOwnerBatch<Owner>
Conclusion: Spring Data JDBC does not support batch operations. To avoid negative performance impact after migration to Spring Data JDBC, we need to monitor the generated SQL closely and implement batch operations where required. Thanks to the repository extension mechanism, it is not a very complex operation.
Epilogue
Replacing the data access framework is not just about changing API calls. It’s also changing the development approach and adjusting existing business logic according to the new data access framework philosophy. Though similar, Spring Data JPA and Spring Data JDBC are pretty different in terms of APIs, supported features, and best practices. The replacement will cause not just local changes but almost total code review, including business logic.
So, if you feel that the existing code based on Spring Data JPA does not work well, try to figure out what is going on and fix it within the current framework.
Wrong SQL? We can try to:
- Rewrite derived methods with JPQL
- Use Entity Graphs
- Rewrite JPQL to native SQL
Does L1 Cache cause memory overflow? We can review selected data or use shorter transactions.
Using Spring Data JPA, Hibernate or EclipseLink and code in IntelliJ IDEA? Make sure you are ultimately productive with the JPA Buddy plugin!
It will always give you a valuable hint and even generate the desired piece of code for you: JPA entities and Spring Data repositories, Liquibase changelogs and Flyway migrations, DTOs and MapStruct mappers and even more!
Need complex queries and mappings? There is no need to replace JPA in the whole project. We can do it locally in those parts requiring complex queries and use another data access framework.
If we decide to replace Spring Data JPA with another framework, namely Spring Data JDBC, then we should pay attention to the following areas:
- Associations. We need to figure out how the framework deals with the related entities and how to fetch and update them.
- Lazy fetching. Whether or not it is supported and how to limit data if the framework does not support it.
- ID generation.
- Batch operations.
- Entity state tracking.
- Derived queries in Spring Data Repositories
- JPQL. How to replace it properly.