JPA Buddy 2022.3.0 is out! In this release, we introduce completely new features like "Generate DDL by Entities" and "Extract to MappedSupperclass" action and many improvements: Reverse Engineering, IBM Db2 support, and others. Let's have a look at the most noticeable changes in detail.
DDL Generator
Generate DDL by Entities action allows developers to convert entities into DDL statements in a couple of clicks. It can generate:
- Initialization scripts to create a database schema from scratch;
- Differential DDL to update the already existing database to the valid state in accordance with JPA entities.
Also, this feature is extremely useful if we want to avoid using the automatic scripts generation enabled by hbm2ddl or ddl-auto properties. By using the JPA Buddy action, you can fully control DDL before execution, setup proper Java -> DB types mapping, map fields with attribute converters and Hibernate types, generate drop statements, and many more.
Extract to MappedSuperclass
Everyone knows "Extract Superclass" refactoring in IntelliJ IDEA. Now, JPA Buddy allows you to do the same with JPA entities. We can easily extract attributes along with JPA annotations to MappedSuperclass and build a well-designed entities hierarchy.
Generate entities from DB tables
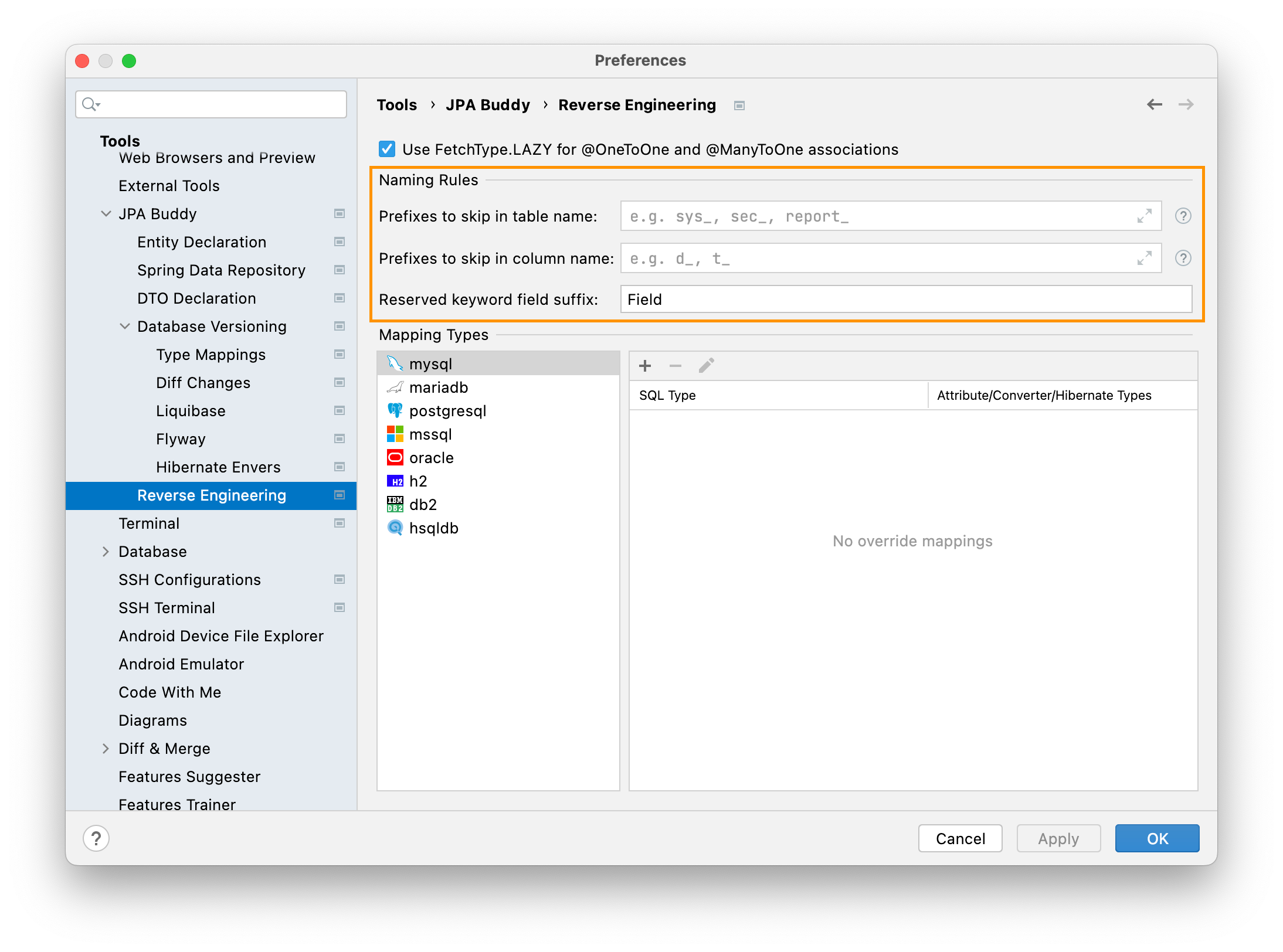
Naming rules for reverse engineering is another topic covered by JPA Buddy. Naming conventions for database objects are pretty important, especially for big databases. We often see SYS_, DBA_, PG_ or other prefixes in DB schemas. In Java, we usually do not use suffixes for class names, we use packages. So, we can safely skip prefixes in JPA entities class names during reverse engineering process. JPA Buddy allows us to specify suffixes in a comma-separated list list like SYS_, PG_ in the plugin settings. Hence table named PG_LARGE_OBJECTS will be transformed into LargeObject entity.
Also, the column name might match the reserved Java keywords in some cases. Obviously, it's not possible to create an attribute named public. For such cases, JPA Buddy allows you to define field suffix, e.g. Field like in the picture below. So, the column named public will automatically turn into a publicField attribute.
Spring Data JPA
When we have a lot of entities, creating repositories for them one-by-one becomes a boring job. You can now create repositories twice, thrice, or as many times faster as you want. This became possible thanks to the new bulk repository creating action. To create Spring Data repositories for a bunch of JPA entities, you need to select entities in the project tree, invoke the JPA Buddy wizard, adjust your selection and that’s it. Look how this feature can accelerate the development process:
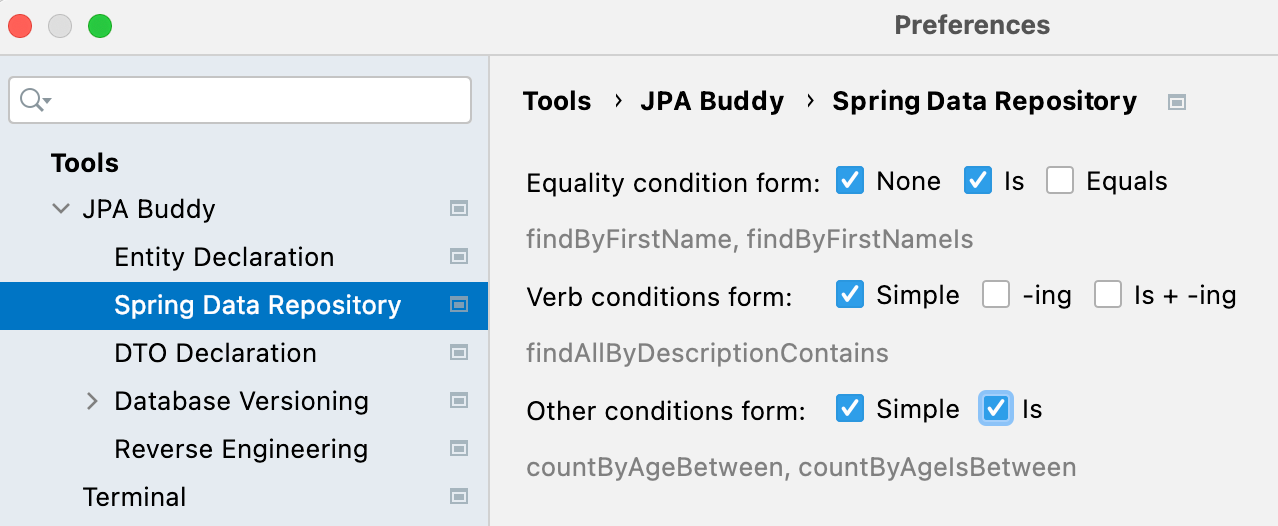
Also, when you move further to creating query/derived methods in the generated repositories, you can find another improvement very handy: naming standards compliance. Spring Data provides several keyword expressions (e.g., Containing, IsContaining, Contains) for method names. On the one hand, it gives us some flexibility in methods naming. On the other hand, in big teams, different naming for the same actions may be confusing for code reviewers and maintainers. If you have naming standards established for the development team, you can configure JPA Buddy to use only approved keywords for method names generation:
Using Spring Data JPA, Hibernate or EclipseLink and code in IntelliJ IDEA? Make sure you are ultimately productive with the JPA Buddy plugin!
It will always give you a valuable hint and even generate the desired piece of code for you: JPA entities and Spring Data repositories, Liquibase changelogs and Flyway migrations, DTOs and MapStruct mappers and even more!
Conclusion
In this article, we have reviewed only some of the features and improvements that were added to the latest release. Find the full list in our issue tracker (65+ resolved issues). Share your feedback and ideas in our Discord channel and follow us on Twitter to get the latest news about JPA Buddy along with useful JPA tips!